swim
December 29, 2025
tldr: check out swim!
There was once a time (circa 2018) when Spotify used to host a website: spotify.me. It redirects to the normal web app now, but it was effectively the precursor to the yearly Spotify Wrapped. I missed being able to see this on demand, and thought it’d be fun to see what other stats I could figure out on my own. Conveniently, Spotify allows you to download your extended listening history, which has all of your listening history from the start of time. In gory detail.
Here’s what a listening example might look like (with some omissions):
{
“ts”: “2019-05-17T17:55:55Z”,
“ms_played”: 216623,
“master_metadata_track_name”: “Good Things Fall Apart (with Jon Bellion)”,
“master_metadata_album_artist_name”: “ILLENIUM”,
“master_metadata_album_album_name”: “Good Things Fall Apart (with Jon Bellion)”,
“spotify_track_uri”: “spotify:track:6pooRNiLyYpxZeIA5kJ5EX”,
“episode_name”: null,
“episode_show_name”: null,
“spotify_episode_uri”: null,
“reason_start”: “clickrow”,
“reason_end”: “trackdone”,
“shuffle”: false,
“skipped”: null,
“offline”: false,
“offline_timestamp”: 0,
“incognito_mode”: false
}Well. If you look at it, it seems like there’s more than enough data to work with.
My first iteration of this is old. So old, that the only way I had to visualize this was an ugly matplotlib graph.
graph from 2021 ryan :)
You can tell I a) didn’t know how to code, and b) it was old, because it’s a hideous plot, and ChatGPT didn’t exist yet, or else it’d be much prettier and have labels (because chat would have written it). I still can’t write a matplotlib chart (other than plt.hist or plt.plot), but I certainly can have chat or Claude do it for me!
Then, at the end of 2022, I rewrote it: this time, to a web UI, inspired by the github contribution graph. I made it somewhat interactive, with some tooltips displaying your top songs for the day. Pretty cool, I thought! And this was at the beginning of LLMs, so I used them a bit but they were far from what they are today—shocking progress in the 3 years since.
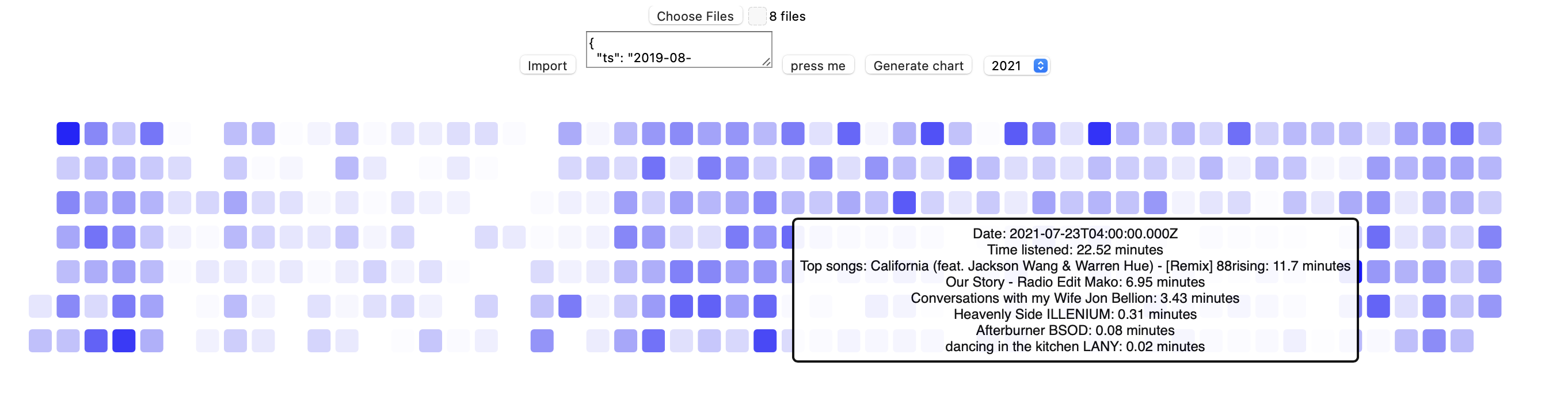
sf boy listening aside, as I was digging through the archives, I discovered that I originally named it swim like vim is to vi: it’s Spotify Wrapped Improved. Tylenol baby
It’s been 3 years since, and I haven’t touched this project. But every year, I have still been downloading my data and shoving it in. In fact, I’ll even tell some of my friends this is a thing they can do. But, nobody is going to download the code and host it themselves, and it’s ugly enough that I wouldn’t put it publicly, so I decided to give it a revamp. And anyways, I haven’t built something fun in a while, and haven’t had the opportunity to use Claude at what it’s best at. 4 days into a $20 subscription later, the final product is something I’m pretty happy with.
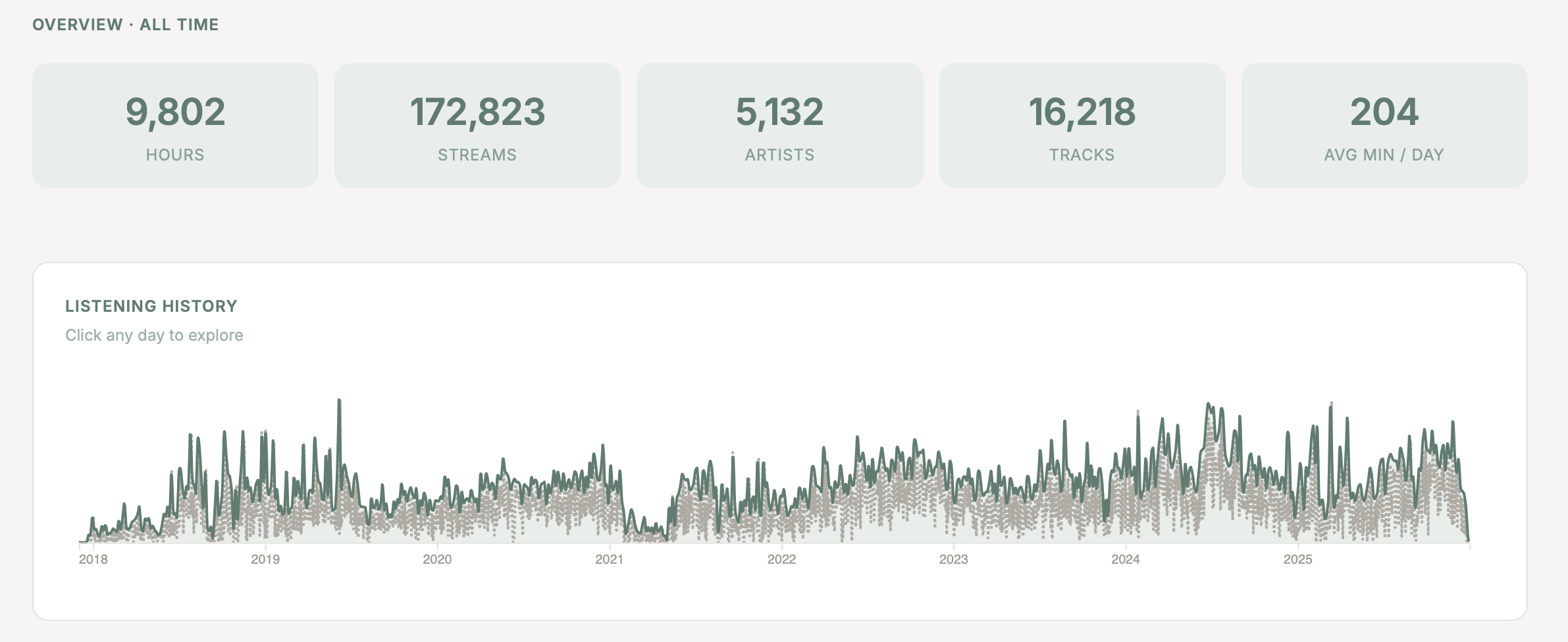
so much listening
I think the amount of usefulness is proportional to the amount of music you listen to and how it records parts of your life, and there’s two fun things I’ll point out for my own swim:
The first one is a bit obvious from the graph: I took some time “off” Spotify in early 2021, and it’s funny how noticeably my usage dipped off. Like, this is expected, but it’s still fun to see in the data.
Secondly, I have this one playlist that I listen to when I’m “locked in”, and sometimes I wonder how “locked in” I have been over time.

I fell off
Clearly I have been locked out recently, but if I zoom into the left part, I can count ~ 120 streams of each song in the playlist, and since it’s a playlist I play sequentially, it means I’ve probably played it around that many times: for a playlist that’s around 2 hours, that is about 240 hours of being locked in over those few months (this roughly corresponds to my cf time during covid haha).
This is super specific to me, but one of the things I remember about my music listening that I’ve always been excited to find an answer to, and swim has enabled that. It also can enlighten me on some beliefs I have associated with music, for example, there was this song I associate to some period of time in my life, but when I inspect the listens, the timeline doesn’t match up! Unreliable narrator indeed… But music is certainly something that underscores so much of my life, and many songs and artist coincide with different periods of my life it is fun to explore some parts of life I haven’t thought about in a while—if I have excited anyone to look into their listening history, or be able to answer some random question they’ve had, then swim has done its job. It’s AI slop, but it’s tasteful AI slop :).
Tidbits
Two things I thought were interesting as I built this app, and claude certainly did not come up with these ideas.
Searching DSL
did you know the guy who made racket teaches at MY university?
The search, as noted on the website, defaults to a naive substring match on the artist or track name. Thus, if you type just into the searchbar, you’ll match Justin Bieber but also songs like Just Another Girl by Aespa which may or may not be what you’re looking for. To aggressively filter, there’s an advanced S-expression based query language.
The query language matches each listening record, and checks whether or not that record passes. Here’s a list of predicates in a semi-formal grammar:
<predicate> := (artist <match>) | (track <match>)
| (year <year-expr>) | (date <date-expr>)
| is_track | is_podcast
<match> := word | string | regex
> rzhu: word does not need quotes, string has quotes, regex is delimited by a `/`
<year-expr> := <comp> YYYY
<comp> := <= | >= | =
<date-expr> := YYYY-MM-DDYou can then compose these using the operators and, or, and not.
So, a query is something like
<query> := <naive> | <expr>
<naive> := string
<expr> := <predicate> | (<operator> <expr-list>)
<operator> := and | or | not
<expr-list> := <expr> <expr-list> | Empty
> rzhu: the predicates should follow the arity: and/or are n-ary, not is unaryThere is exactly one truly special case: if the tokens is_track or is_podcast do not show up in your query (in both native and advanced queries!), then your query will automatically be filtered to only consider tracks. In other words, if you have a query q, it will be wrapped as (and is_track q). This feature is for Zack because he’s the only one that listens to podcasts regularly, and it would be cool to have a way to filter them in/out (update: Adrian also claims to benefit from this).
A naive query s is equivalent to the query (or (artist *s*) (track *s*)), as we are matching a substring, or in full regex (or (artist /.*s.*/i) (track /.*s.*/i))
The most useful queries I have found are simply queries for a specific song for a song with a common title, so you can match on both artist and track. Otherwise, this was mostly an exercise in seeing how much claude code could do which I’ll discuss below.
Number of Streams
Spotify ranks your top songs for the year by number of streams—I think this is wrong, but Spotify can do whatever it wants. Counting the number of streams is a pretty open ended problem: what counts as a stream? After all, one of the fields in the listening record is reason_end: you can probably filter for trackdone, and call it a day. This is pretty unsatisfying to me! To be honest, this might be correct almost all the time, but what if you skip a song in the last bits? What if the dj does something to mangle the song durations? What if you start in the middle? I don’t know these answers, but I did have a more fun way to do it: we can add up all the time you listened to a song, and divide it by the song duration.
It’s easy to get the total duration: just loop over the data. How do we get the duration? It’s harder than it looks: I don’t have an API call (I don’t want to have one either: querying for tens of thousands of songs would be expensive and pointless)! Let’s look at what we have to work with.
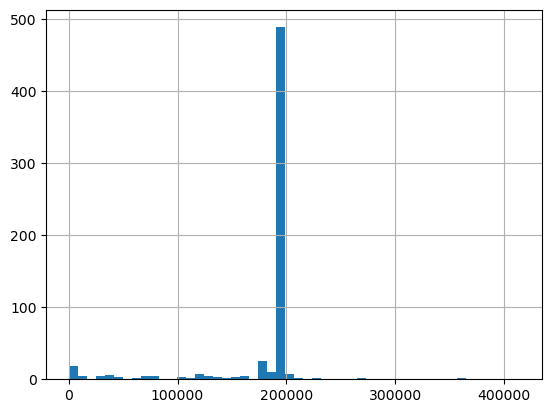
`ms_played` histogram for a single song. The actual duration is clearly around 200 seconds
In the histogram above, we can see that the main mass of listens is around 200 seconds, but there’s some to the left, which are expected (skips/incomplete listens), but there’s also some to the right? what do these mean? I have no idea: my best guess is if you scrub backwards it counts as the same listen, but longer. Or, sometimes, when I hit my downtime and Spotify gets time limited, it will play silently: not actually playing, but it’s like shadow playing. And then when the screen limit bypass hits, it scrolls back.
Whatever the reason, we need to algorithmically determine the point mass above, and I can’t just take the max. Here’s a random sampling of tracks and their histograms:
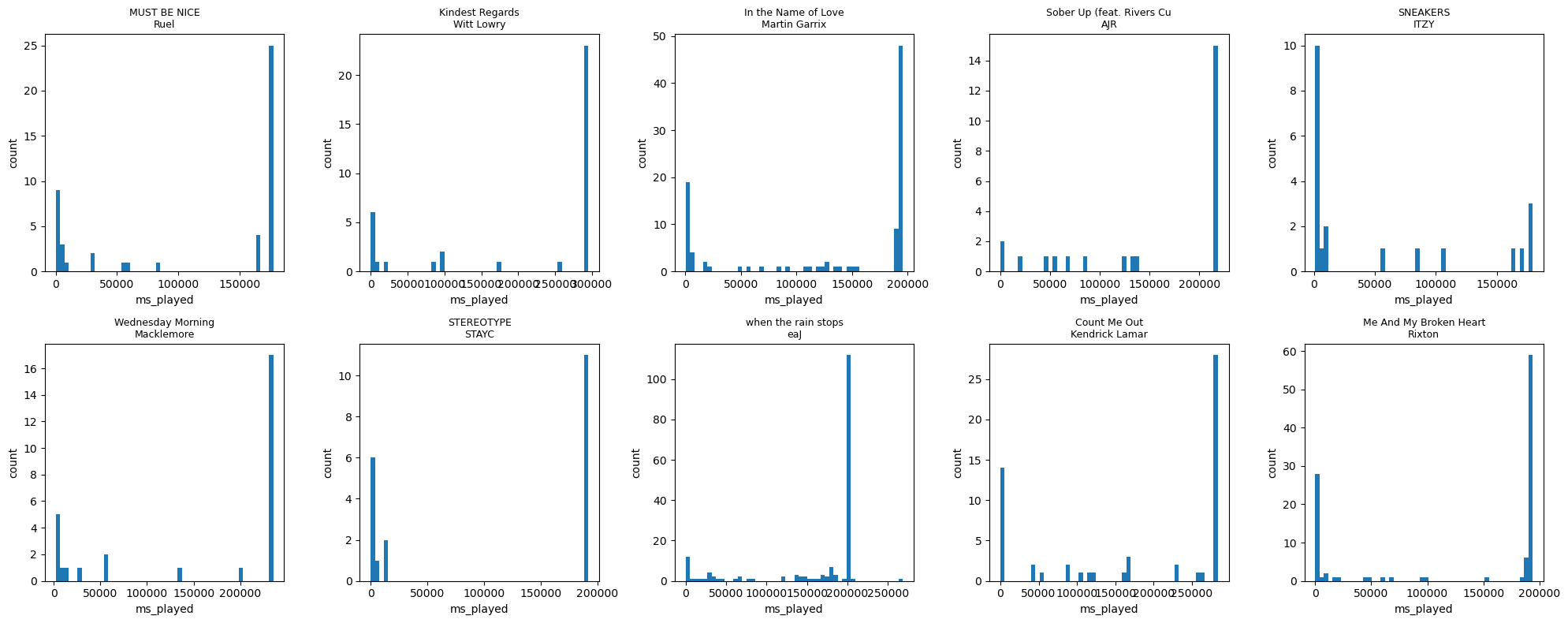
many histograms!
So, it seems that picking the largest point mass (has > 1 occurrence) is a pretty good approximation of listening duration. It even works for the top right, which is a song I mostly skip!
How does this actually do? To test, I hit the Spotify API and saved the durations of the 17,961 songs I’ve listened to and benchmarked the following algorithm: pick the maximal listening cluster if it exists, and pick the max otherwise.
def cluster(durations):
counts = durations.value_counts()
repeats = counts[counts > 1]
if not repeats.empty and repeats.index.max() > 0:
return repeats.index.max()
# no repeats
return durations.max()Running this against our benchmark, it scores an accuracy of… 62.5%. This seems kind of trash.
What kinds of predictions is it failing? Am I not listening to a song all the way through enough? I don’t really know what could possibly go wrong—for pure curiosity (ego), let’s see how good we could get in theory (surely I can’t be that far off). I’ll make the assumption that the durations list isn’t rich enough to generate a listening time that we don’t observe, so our optimal algorithm is to just pick the closest listening duration that we observe:
def theoretical_best(duration, oracle): # oracle is the actual duration
closest = None
min_diff = float(‘inf’)
for d in duration:
diff = abs(d - oracle)
if diff < min_diff:
min_diff = diff
closest = d
return closestCool! Let’s benchmark it and see what we g—63.3%. Okay it seems like we’re actually fine.
But why is this now so low? Let’s look at some cases where the algorithm is off:
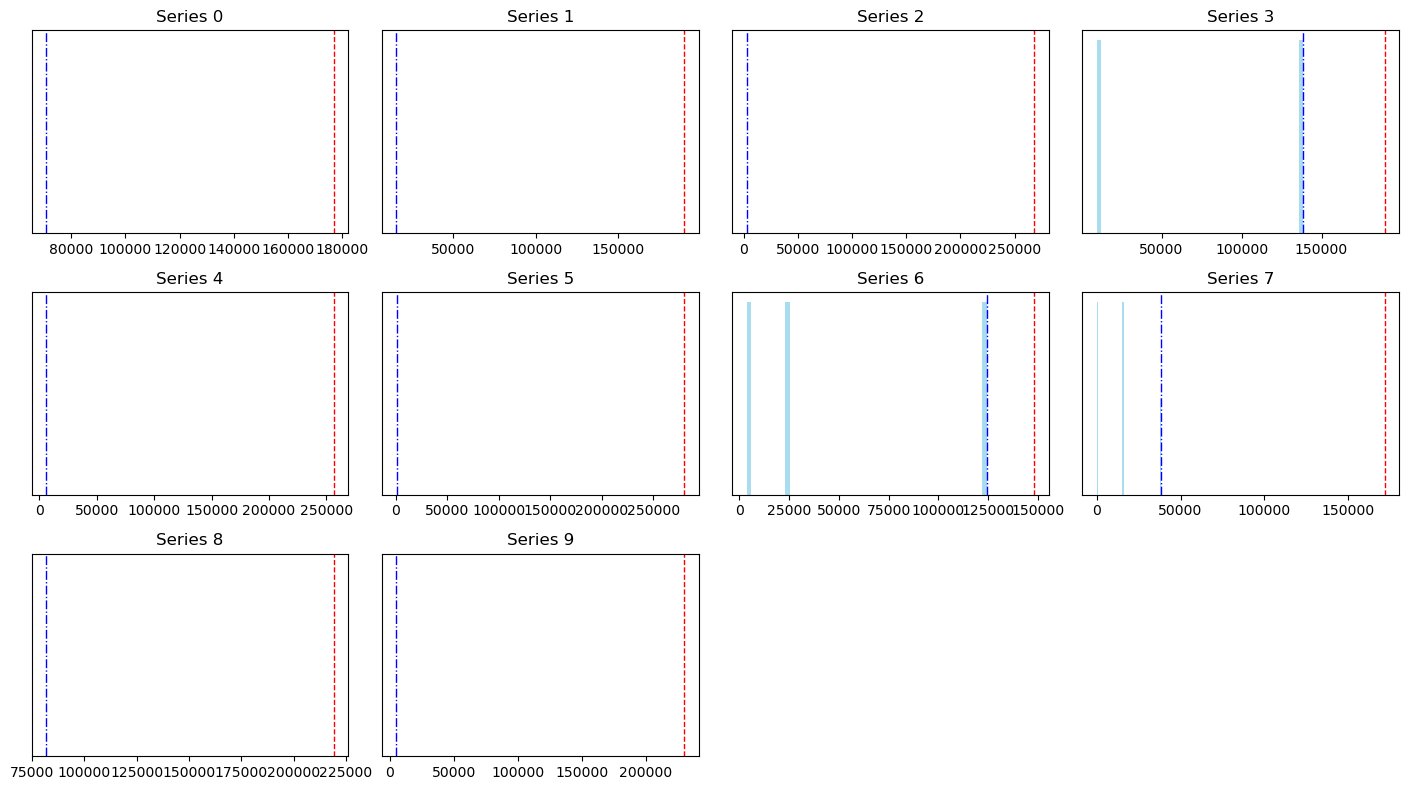
why does the theoretical best suck?
The red line denotes the actual listening time: this mostly looks like songs where I’ve listened to it about… once. And skipped it instantly. So, it doesn’t seem like there’s a possible way to get around this! And if we think about it, being “wrong” for these songs with respect to stream count isn’t so bad: it’ll be 1 anyways! A bit frustrating, but it seems to not be a problem. Checking against my wrapped 2025, the stream count is off by at around 5% at worst, which I’m going to attribute to Spotify tracking plays a bit smarter than me (I am just doing listening time divided by inferred duration). Maybe I am giving Spotify too much credit, but it doesn’t seem like there’s very must to refine here.
This also like doesn’t work for podcasts, because a) most people don’t listen to podcasts in once sitting, and b) most people don’t listen to podcasts more times so this isn’t even interesting. So I just said every podcast always gets 1 stream, no matter how long you listened to it for. Another Zack feature :).
To be pedantic, accuracy is # of predictions within 5 seconds of the actual duration returned by the API for a 80% subset of the 17,961 songs I’ve listened to. Yes, I did actual experiments with this. No, I will not run my jupyter notebook in the magic order to run this against the full dataset. So much for reproducible science.
Fun fact: if you simply take the max, you’ll get 58.4% accuracy which is okay but shockingly bad in comparison! And this is bad in exactly the wrong case: when I have more listens in a song, the more likely the data was to be somewhat corrupt and have bad max samples. And thus, the stream count will be deflated (many of my top songs were reported to be 2x as long as they actually were!).
Claude Code
my intern al is goated
I haven’t written serious javascript since 7th grade, and that still remains true. Claude was unbelievably good. So good, in fact, that I’m wondering if I will have a job in a few years.
It one shot basically every task I gave it: iterating over a few days, and some manual interventions from me, I’d estimate 99% of the code written in the repo is written by Claude. Granted, this is roughly one of the strongest usecases of LLMs: a webapp, writing Javascript, HTML, and CSS. And I’m extrodinarily inexperienced with web development, so I’m probably easy to impress. But it was still awesome! Like for instance, it fully one shot the parser + compiler for the little query language, without any bugs, which kind of blew my mind.
I’m reminded of a quote by Ira Glass:
Nobody tells this to people who are beginners, I wish someone told me. All of us who do creative work, we get into it because we have good taste. But there is this gap. For the first couple years you make stuff, it’s just not that good… But your taste… is still killer. And your taste is why your work disappoints you. A lot of people never get past this phase, they quit.
I think I made swim because I’m curious about my listening history, which drives my taste to be decent (in my opinion)! I certainly don’t have skill (this is evidenced by my previous attempts). Claude let me “cover” my gap in skill, and create something that roughly matched my taste, without skill or practice.
The quote continues:
Most people I know who do interesting, creative work went through years of this. We know our work doesn’t have this special thing that we want it to have. We all go through this. And if you are just starting out or you are still in this phase, you gotta know its normal and the most important thing you can do is do a lot of work. Put yourself on a deadline so that every week you will finish one story. It is only by going through a volume of work that you will close that gap, and your work will be as good as your ambitions. And I took longer to figure out how to do this than anyone I’ve ever met. It’s gonna take awhile. It’s normal to take awhile. You’ve just gotta fight your way through.
It’s certainly something to think about. In this case, it’s not something I’m particularly interested in getting more skill in, so I’m not concerned. But it must be so easy, to take LLMs as a crutch and use it as a replacement for skill. This is pretty clearly evidence by people stumbling through school, and certainly some habits I’ve had while working.
In some ways, this is natural, as technology grows humans adapt: we don’t need to memorize multiplication tables anymore (maybe this is a bad thing) or do complicated computations by hand, phone books don’t quite exist anymore, and pictures are getting easier to take and better year by year. In many ways, this is great! Hand-done computations were slow, and prone to errors. Phone books are bulky, and we can just have little contact books within our phones for eternal record keeping. Pictures are sharp, easy, and convenient: memories are easy to record, and anyone can share their life from anywhere, at any time. But there’s also some lost art: film photography still has a significant following, and dedicated cameras are still a serious line of work! The other two are more or less fully dead, but the question remains. What will it let us keep, what will it kill. What will become niche and hobbyist, and what will become more and more important to be able to do as a human?
After all, before computers, nobody programmed (by definition). Now, the largest companies in the world are all centered around technology. I’ve heard some descriptions of the rise of LLMs as “making intelligence cheap”. So the question is, how will LLMs augment us? And what does this mean for me, and for varying people around the world?
I, of course, don’t have an answer to this question. This is a post about Spotify listening history for crying out loud.
Conclusion
I promised some recs in my blog, so here they are
For my last blog post of the year, some parting favorites.
Some favorite reads (this is a victim of recency and me remembering to save bias):
- The Alchemist
- I Love You. Please Find Someone Else.
- being too ambitious is a clever form of self-sabotage (I read this when it was not paid and remembered I liked it)
- after my dad died, we found the love letters
- lvaules
Some favorite media:
- Zootopia 2 (I am so dead serious)
- The Great Gatsby Musical
Frankly, there’s very little technical work or reading I did this year. A theme for next year. After all, 2025 was the year of whimsy.
Thanks to Zack and Armina for feedback! Everyone else too who tried it out is also appreciated (but less so <3. I’m kidding. Much appreciated)